

200ms p99 cold latency at 100B+ scale, with <1GB RAM per billion vectors goals:
Scale ⬆️ recall value ⬆️ latency ⬇️ cost ⬇️ Memory ⬇️
indexing:
HSNW:
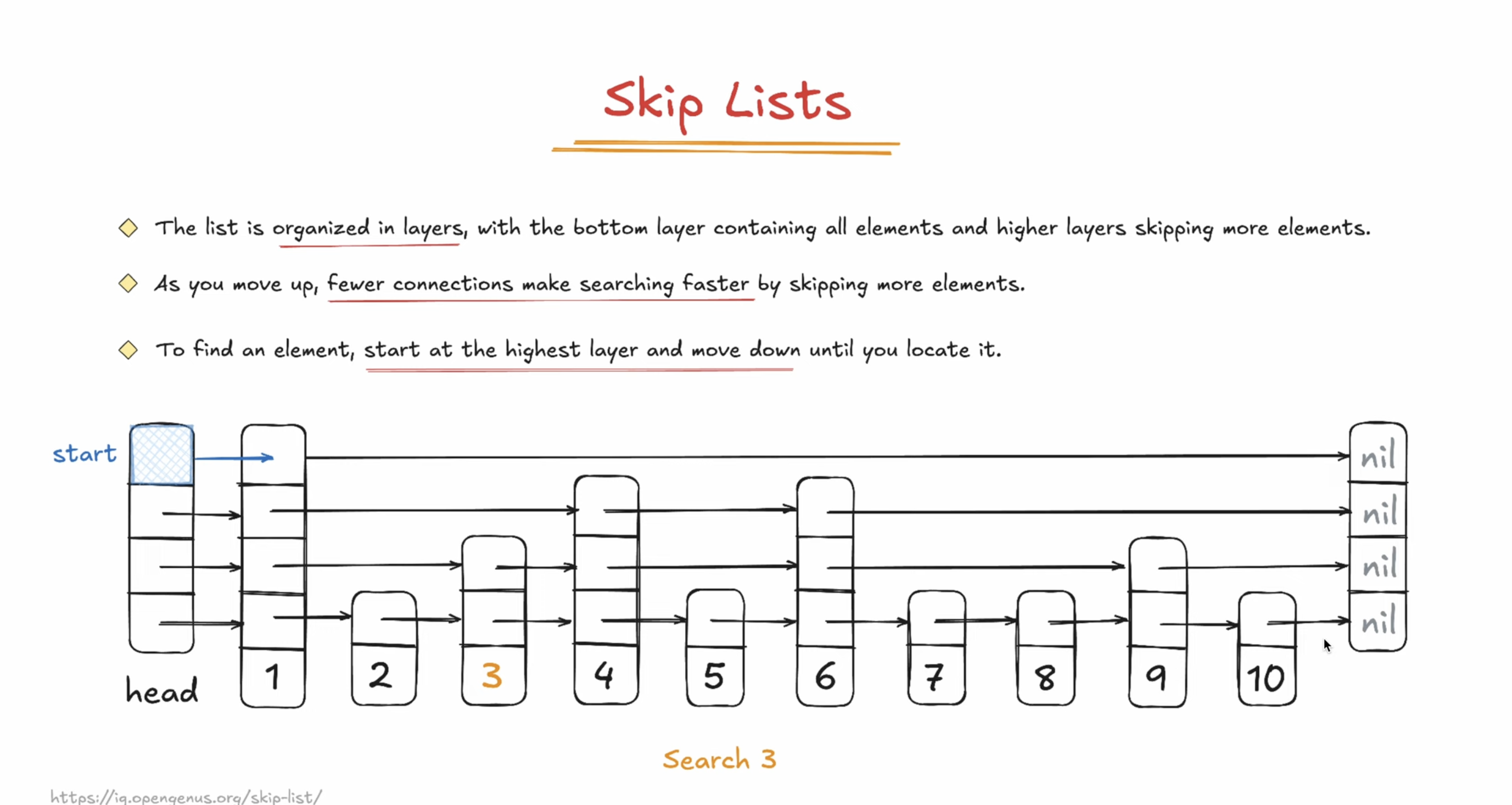
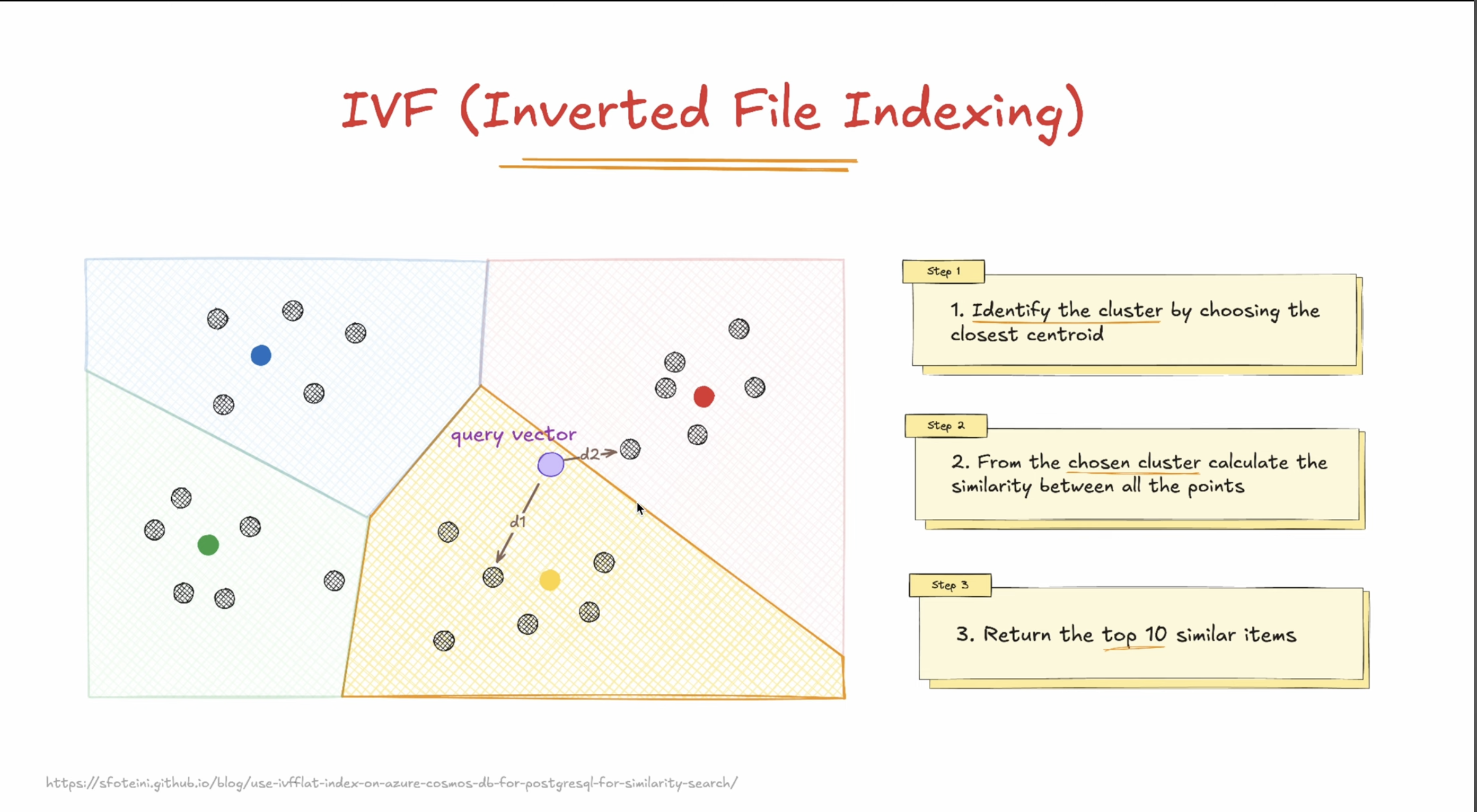
IVF:
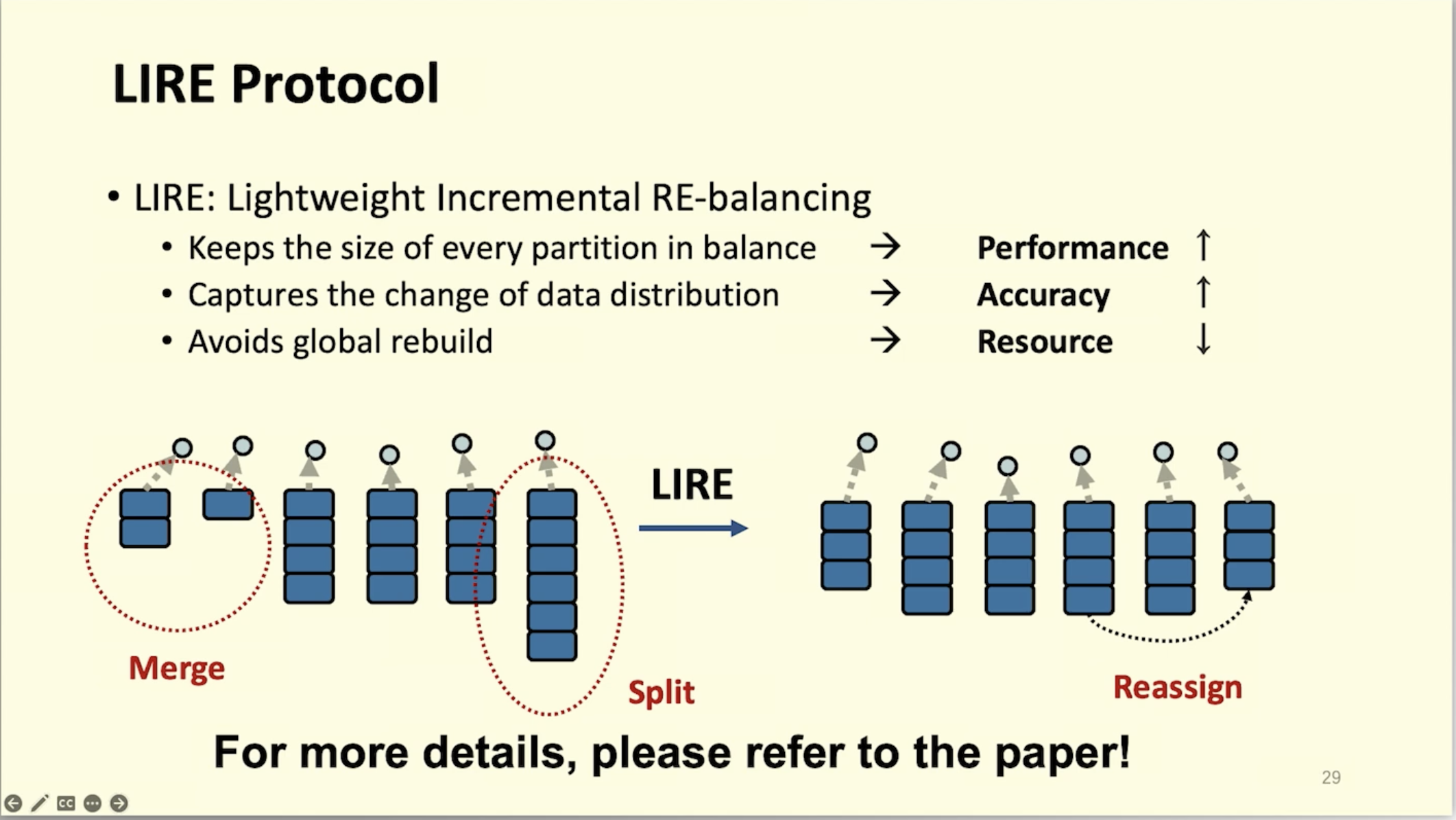
LIRE:
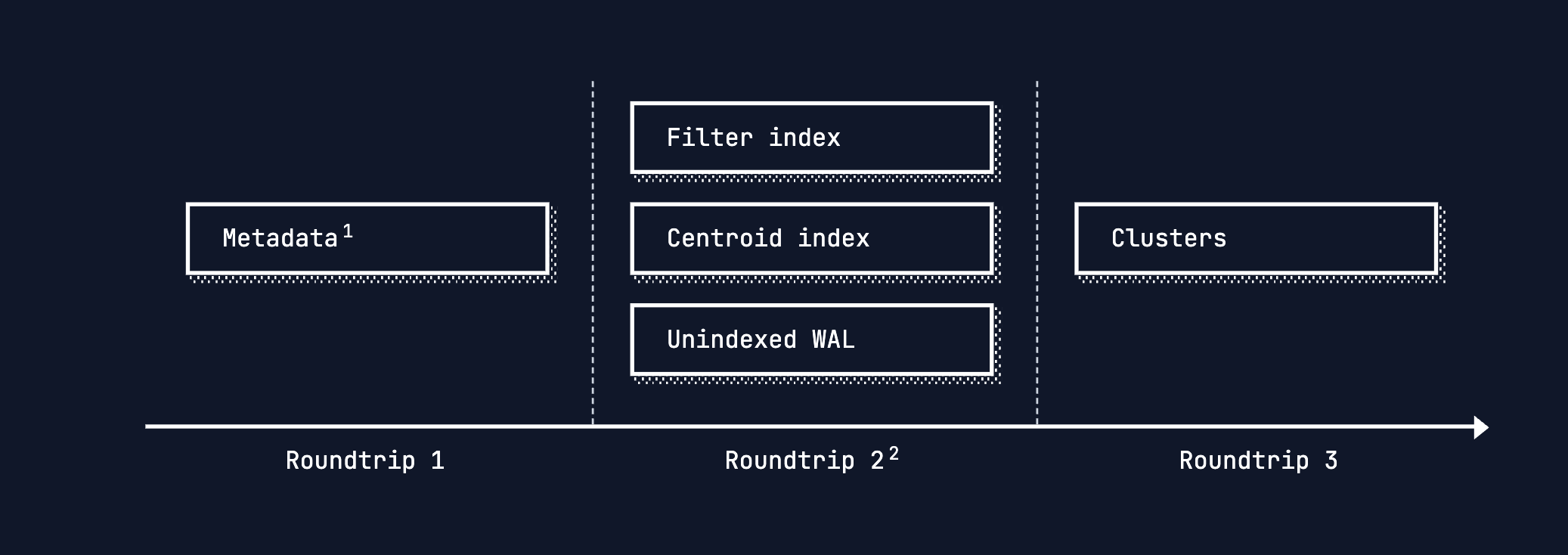
limitation or problem faced by turbopuff:
- Glob filters and regexes can be expensive.
Glob tpuf*is compiled down to an optimized prefix scan, whereasGlob *tpuf*orIGlobwill potentially scan at every document in the namespace. Contact us if you’re seeing performance issues for your workload, we can likely suggest alternatives (e.g. using full-text search or a different filter). This is not a fundamental limitations, and we plan to introduce indexes for these types of queries soon. -
- Use Python with C bindings. If you’re using the Python turbopuffer client, use the
turbopuffer[fast]package rather than the base package. This includes C binaries which can improve ingestion throughput dramatically, by leveraging a faster JSON serializer.
- Use Python with C bindings. If you’re using the Python turbopuffer client, use the
https://turbopuffer.com/blog/native-filtering
Core Idea: “Write a new version, read the merged view”
| Traditional DB (Mutable) | S3 + LSM (Immutable) |
|---|---|
| UPDATE row SET x=5 → modify disk block | INSERT (key, x=5, ts=NOW) → new SSTable file |
| Read → one block | Read → merge latest versions on-the-fly |
Immutability is not a bug — it’s the foundation of durability.
https://github.com/quickwit-oss/quickwit, is similar on s3 but the records are immutable
S3 / GCS / Azure Blob Storage
!!! tip “Lowest cost, highest latency”
- **Latency** ⇒ Has the highest latency. p95 latency is also substantially worse than p50. In general you get results in the order of several hundred milliseconds
- **Scalability** ⇒ Infinite on storage, however, QPS will be limited by S3 concurrency limits
- **Cost** ⇒ Lowest (order of magnitude cheaper than other options)
- **Reliability/Availability** ⇒ Highly available, as blob storage like S3 are critical infrastructure that form the backbone of the internet.